Subsections of Mes idées
Dette technique
1/ Définitions sur le net
- Ward Cunningham (1992) : if you develop a program for a long period of time by only adding features and never reorganizing it to reflect your understanding of those features, then eventually that program simply does not contain any understanding and all efforts to work on it take longer and longer.
- James Shore : the cumulative total of less-than-perfect design and implementation
- Tom Poppendieck : everything that makes your code harder to change
2/ Ma définition
La dette technique
- est constituée des imperfections de conception et de développement
- nuit la productivité de l’équipe
- réduit la maintenabilité
- augmente le nombre d’erreurs (bugs dans les nouvelles fonctionnalités et régressions dans le code existant)
- se mesure par l’effort qu’il faut pour la résorber (c’est aussi la définition de la dette technique de Sonar)
Ces imperfections/violations se séparent en 3 groupes :
- les imperfections identifiées et délibérées : elles sont les preuves de mauvais choix faits en toute connaissance de cause. Ces choix doivent impérativement donner lieu à un plan d’action pour résoudre le problème. Exemple : pas de mesure de la couverture de code ni de vérification des exigences qui y sont liées dans un premier temps à cause des délais. Mais on y reviendra juste après la livraison (les promesses n’engagent que ceux qui y croient).
- les imperfections involontaires et relevées par un outil : elles sont les preuves d’une erreur, incompétence ou d’une méconnaissance. Exemple : les violations relevées par Sonar sur code “commité”. Ces violations doivent être traitées au plus vite par leur auteur. Ainsi il apprendra de ses erreurs et ne recommencera plus (personne n’est pas parfait).
- les imperfections involontaires et non identifiées : elles sont souvent identifiées durant la résolution d’un bug. Le problème est général à tout le code mais c’est un code en particulier qui a fait émerger un problème. Il faut alors ajouter une règle de développement sur le projet (documenter la règle et l’intégrer dans les outils de vérification). Exemple : un caractère bizarre dans une page WEB va permettre de se rendre compte qu’une partie des fichiers “source” n’est pas en UTF8.
La dette se traite
- en définissant au plus tôt des règles de conception, de développement et de test
- en mettant en place des outils (sur le poste du développeur et dans l’intégration continue)
- en sensibilisant/formant les développeurs pour qu’ils génèrent moins de dette
- en attribuant une priorité à chaque imperfection existante (ou type d’imperfections)
- en organisant des actions de refactoring pour réduire le nombre d’imperfections (investir dans la qualité du code n’est pas une perte de temps mais un investissement)
- en amendant et enrichissant les règles tout au long du projet
3/ Sources
Liens sur des pratiques utiles
Pratiques de développement :
Documentation d’une solution, d’un langage ou d’un projet :
Pratiques triés par méthode/framework :
- Scrum :
- objectifs de sprint
- sprint backlog
- product backlog
- burn-down chart
- DefinitionOfDone
- XP :
- integration continue
- 10 minute build
- whole team (toutes les compétences au même endroit)
- informative workspace (management visuel et partage des informations)
- test-first programming
- pair programming
- incremental design
- user story
- slack (se garder du temps pour les impondérables, l’amélioration continue, …)
- refactoring
- simple design
- planning game
- single code base (une seule branche, les autres durent moins de quelques heures)
- shared code (le code n’est le domaine réservé de personne, tout le monde peut contribuer à toutes les parties)
- code & test
- root cause analysis (corriger les bugs et faire en sorte de ne plus les reproduire)
- real customer involvement
- daily deployment (en prod chaque nuit)
- pay-per-use (c’est le meilleur feedback et il doit revenir jusqu’à l’équipe)
- LEAN :
- réduire le gaspillage
- Intégrer la qualité dans le processus de production
- Créer et améliorer la connaissance
- Différer le plus tard possible les décisions irréversibles
- Produire rapidement une solution utile
- Respecter les personnes
- Optimiser le tout
- UP :
- itératif et incrémental piloté par les risques
- gérer la demande par les Use Case
- architecture par composants
- concevoir visuellement (vue logique, vue implémentation, vue comportement, vue déploiement et vue utilisateur)
- tester et vérifier la qualité
- controler les changement
- phases IECT
- Agile UP :
- US plutot que UC
- storyboard
- Agile model driven development = Model Storm (réunion de 30mn de conception) + TDD
- moins de document que UP
Tests de développement
1/ Coup de gueule en introduction
J’en ai ras le bol de ce débat stérile sur les tests unitaires. Chacun a sa petite définition et, en fonction du contexte, utilise mal l’adjectif unitaire.
2/ Discutons
D’un côté, les tests sont unitaires quand le SUT (System Under Test) se limite à une classe voire une méthode. L’avantage de ces tests est qu’ils sont assez simples à rédiger car le code à tester se limite à celui de la classe (inutile de connaître le comportement de tous les autres composants du système qui peuvent être mis en jeu). Le problème est qu’il faut justement arriver à isoler le SUT et donc utiliser des techniques de bouchonnage (encore un framework que les collaborateurs du projet doivent apprendre à maîtriser).
De l’autre côté, les tests sont unitaires du moment qu’ils participent à la construction de l’application durant les travaux du développeur (j’aime les chefs de projet définissant un nombre de jours de “programmation et tests unitaires”). Dans cette définition, n’est pas pris en compte la granularité du SUT.
La troisième définition (la pire à mon sens) est le test basé sur JUnit.
Et si, pour se simplifier la vie, on parlait de tests de développement utilisant des TU, TI et TA ?
Et là, on me pose la question “Et les tests de non-régression ?”. Ma réponse est simple “Un test de non-régression a été un test de développement mais le développement est fini et le test est resté.”
Créer une console Hibernate
1/ Qu’est-ce ?
Une console Hibernate est un environnement de développement (IDE) permettant de requêter en HQL (ou JPQL) une base de données.
L’intérêt de cette console est de tester une requête HQL sans avoir à déclencher du code Java dans l’application ou dans un test de développement.
2/ Les problèmes
Où se trouve la difficulté ? Un peu partout en fait :
- Il faut trouver comment installer le plugin Eclipse.
- La console Hibernate de JBoss Tools utilise encore un fichier hibernate.cfg.xml dont on a plus très souvent l’habitude.
- La recherche d’entités par présence d’annotation n’est pas disponible (c’est Spring qui le fait d’habitude).
- il faut paramétrer correctement la connexion à une base de données.
3/ Une solution
3.1/ étape 1
Pour installer le plugin, démarrer Eclipse puis
- accéder au MarketPlace via le menu Help > Eclipse MarketPlace
- faire une recherche avec le mot jboss
- sur la ligne JBoss Tools xxx, cliquer sur le bouton install
- parmis la liste des fonctionnalités du plugin, ne sélectionner que les packages marqués required et Hibernate Tools
- valider toutes les étapes suivantes jusqu’au redémarrage d’Eclipse (nécessaire pour prendre en compte le nouveau plugin)
3.2/ étape 2
Pour paramétrer la connexion à la base de données, depuis Eclipse
- ouvrir la perspective Hibernate
- afficher la vue Data Source Explorer
- faire un clic droit sur Database connexion
- cliquer sur new
- sélectionner le bon type de base de données et lui fournir un JAR contenant un driver (dans le repository Maven, org.postgresql:postgresql par exemple)
- renseigner les paramètres de connexion
- tester et sauvegarder la connexion
3.3/ étape 3
Pour rassembler la configuration dans un même endroit, il faut créer un projet Java dans Eclipse utilisant le même JDK que celui utilisé pour démarrer Eclipse.
La configuration de la console Hibernate demande la création de deux fichiers. Donc, dans ce projet, créer les deux fichiers :
- hibernate.properties qui va rester vide
- hibernate.cfg.xml qui va contenir un de ces deux fichiers XML
Pour une BDD HSQL :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="sessionFactory">
<property name="hibernate.connection.driver_class">org.hsqldb.jdbcDriver</property>
<property name="hibernate.connection.password">login</property>
<property name="hibernate.connection.url">jdbc:hsqldb:file:C:/monCheminVersMaBaseDeDonnees/idDeMaBase;readonly=true;files_readonly=true;hsqldb.lock_file=false</property>
<property name="hibernate.connection.username">username</property>
<property name="hibernate.dialect">org.hibernate.dialect.HSQLDialect</property>
<mapping class="mon.package.MonEntite" />
<mapping class="mon.package.EtToutesMesAutresEntitesSansEnOublier" />
</session-factory>
</hibernate-configuration>
Pour une BDD PostgreSQL :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="sessionFactory">
<property name="hibernate.connection.driver_class">org.postgresql.Driver</property>
<property name="hibernate.connection.password">pwd</property>
<property name="hibernate.connection.url">jdbc:postgresql://localhost:5432/mybdd</property>
<property name="hibernate.connection.username">login</property>
<property name="hibernate.dialect">org.hibernate.dialect.PostgreSQL82Dialect</property>
<mapping class="mon.package.MonEntite" />
<mapping class="mon.package.EtToutesMesAutresEntitesSansEnOublier" />
</session-factory>
</hibernate-configuration>
Toujours dans ce projet, il faut ajouter les répertoires des entités :
- faire un clic droit sur le projet
- cliquer sur Properties puis Java Build Path
- dans l’onglet source, ajouter des Link sources sur les répertoires contenant les classes des entités
- dans l’onglet Libraries, ajouter des external jars permettant de faire compiler les sources (hibernate-core, javax-persistence, … en fonction des besoins)
3.4/ étape 4
Pour paramétrer la console Hibernate, il reste maintenant à
- dans la vue Hibernate Configurations, faire un clic-droit et un add Configuration…
- renseigner le formulaire avec :
- Nom : ce que vous voulez
- Type : Core
- Hibernate version : votre version d’Hibernate
- Project : le projet précédemment créé
- Database Connection : Hibernate configured connection
- Property file : le fichier précédemment créé
- Configuration file : le fichier précédemment créé
- Database dialect : HSQL ou PostgreSQL
Après un petit clic sur la flèche à coté de votre configuration pour l’étendre, puis un clic sur Session Factory, vous devriez voir toutes vos classes persistantes.
Il est maintenant possible d’ouvrir un HQL Editor depuis un clic droit sur la configuration.
A partir du même endroit, il est possible de créer un schéma de votre mapping.
Coder des ré-essais en Java
1/ Avant : guava-retrying
A une lontaine époque, la librairie guava-retrying était pratique pour définir des méthodes à réessayer en cas d’échec. Mais ce projet n’est plus maintenu.
Documentation : ici
2/ en 2025 : spring-retry
SpringFramework fournit, depuis 2011, une librairie pour faire ça.
En voici la documentation : ici
En voici le projet : ici
Et, enfin, voici un article Baldung : ici.
Relecture, revue et audit de code
1/ Mes définitions
La relecture de code est le travail de tout développeur juste avant de commiter son travail. Tous les outils de gestion de version permettent d’afficher le contenu du commit (git diff par exemple).
Une relecture permet de s’assurer
- que les noms des composants, opérations, attributs, paramètres et variables sont explicites,
- que les commentaires sont utiles et pertinents,
- que le contenu du commit correspond bien aux exigences fournies en entrées (ou au ticket/demande)
- qu’aucun fichier ne sera embarqué pour un simple saut de ligne malencontreux,
- …
La revue de code est un processus outillé qui permet de systématiser une relecture de code par un tiers entre la fin du développement et l’intégration du dit code dans les sources de l’application.
Le processus peut être le suivant :
- Dès qu’un développeur pousse son travail sur le repository, une demande de revue est envoyée à un tiers.
- Ce dernier, en cliquant sur le lien dans le mail, se voit afficher le code à auditer.
- L’auditeur parcourt le code et y rédige ses remarques.
- Si le résultat de la revue est satisfaisant, un simple clic permet au commit d’être intégré à la branche principale.
- Si le nombre de remarques (ou leur sévérité) est trop élevé, une notification est envoyée au développeur pour qu’il corrige son code.
Attention, ce processus n’intègre pas le build de la branche, le déploiement du(es) livrable(s) généré(s) et les tests à réaliser pour valider le développement réalisé.
L’audit de code est un processus consistant à faire une relecture de code de tout le code de la branche principale. Ce processus n’est pas lié à un développement précis. Mais il peut être judicieux d’en réaliser un avant ou après un évènement précis (réversibilité de TMA, montée de version majeure d’un framework, …).
Cette pratique est tout à fait compatible avec les deux autres pratiques précédentes.
2/ Le plus important
Attention, on parle ici de la qualité du code. La conception, les librairies/framework utilisés, … sont une autre affaire !!
Quelques soient les pratiques du projet (revue ou audit ou les deux), l’élément central et primordial est l’échange entre le développeur et le relecteur. Cet échange est le seul garant du bon fonctionnement de ces pratiques !!
Sans lui :
- Le relecteur ne verra pas immédiatement l’utilité de son travail. Il s’en lassera et fera de mauvaises relectures.
- Le développeur recevra une liste de remarque totalement impersonnelle. De plus, certaines remarques peuvent parfois être injustifiées. Un échange verbal peut éviter d’interminables échanges de message.
- le relecteur et le développeur ne pourront apprendre l’un de l’autre que s’ils communiquent directement l’un avec l’autre.
3/ Pour se simplifier la vie
Certaines règles de développement sont aisément vérifiables (avec une petite expression régulière par exemple). Pourquoi ne pas utiliser un outil pour contrôler le code ? Il existe quantité d’outil de qualimétrie pour tous les langages.
Ils ne remplacent pas la relecture humaine mais ils peuvent la simplifier en réduisant le nombre de règles et de points d’attention à contrôler.
En plus des contrôles de qualité automatiques, les actions automatiques sur le poste du développeur peuvent simplifier les relectures de code. Tous les IDE proposent de formatter le code, réorganiser les imports, … à chaque sauvegarde de fichier.
4/ Pour aller plus loin
Pour mettre en oeuvre ces bonnes idées en poussant l’interaction un cran plus loin, il faudrait que le relecteur soit à côté du développeur pour réfléchir avec lui. Le relecteur aurait alors la possibilité de faire des remarques de conception aussi. C’est du pair programming !
Hugo et GitHub:Pages
1/ Introduction
GitHub:Pages est une fonctionnalité très utile de GitHub permettant d’héberger un site WEB en le déposant, tout simplement, dans un dépôt Git.
Hugo est un outil de génération de site WEB à partir de template et de Markdown.
Réunis, ces deux outils permettent de réaliser un site très simplement. Les usages sont nombreux. Mais le premier qui me vient est la documentation d’un projet : installation du poste, règles de conception/développement/test, pratiques du projet, … bref, un guide du développeur.
2/ Objectifs
Les objectifs de cette page sont :
- de disposer d’un repository contenant les sources du site avec des pages en markdown ;
- d’utiliser Hugo pour réaliser la mise en page et générer le site statique ;
- de déployer ce site statique dans un repository GitHub:Pages ;
- de sipmplifier au maximum la génération et la publication du site.
2/ La mise en place de Hugo
Hugo est un exécutable. Il faut donc le télécharger (depuis la page officielle) et le déposer dans un répertoire.
Attention, cet exécutable est dépendant de l’OS. Donc, pour construire le site sur Windows et sur Unix, il faut déposer les deux exécutables.
La première étape est donc de
- créer un répertoire
- y placer l’exécutable de Hugo (en conservant ou non le numéro de version dans le nom du fichier)
3/ Créer le site HUGO avec un thème
Pour créer un site avec le thème LEARN (celui utilisé par ce site), exécuter les commandes suivantes (en adaptant le numéro de version si vous souhaitez le conserver dans le nom de fichier) :
hugo-0.140.1 new site monProjet
cd monProjet
git init
git submodule add https://github.com/McShelby/hugo-theme-relearn.git themes/hugo-theme-relearn
echo "theme = 'hugo-theme-relearn'" >> hugo.toml
mv ../hugo-0.140.1 ./
hugo-0.140.1 server
Le site disponible en local n’affiche qu’une page d’accueil vide et aucun contenu.
4/ Paramétrer HUGO
4.1/ Paramétrage essentiel
Le fichier hugo.toml peut être très vide ou très riche selon les besoins. A mon avis, sont obligatoires les informations suivantes :
# L'URL de base du site
baseURL = 'https://mon.serveur.de.doc/'
# Le nom du thème
theme = 'hugo-theme-relearn'
# La langue du site
languageCode = "fr-fr"
# Le titre du site
title = "Mon super site"
4.2/ Paramétrage propre au thème
De plus, chaque thème apporte des fonctionnalités. Voici la documentation du thème relearn
Par exemple, il est utile/possible de :
[params]
# Thème bleu par défaut mais autres thèmes disponibles
themeVariant = ['blue', 'relearn-light', 'relearn-dark']
# Désactiver le lien 'Home' dans le menu
disableLandingPageButton = true
# Définir l'auteur
[params.author]
email = 'talbotgui@gmail.com'
name = 'Guillaume TALBOT'
# Activer l'impression
[outputs]
home = ['html', 'print']
page = ['html', 'print']
section = ['html', 'print']
5/ Créer un premier contenu
Pour créer une page dans Hugo, il suffit de créer une arboresence dans le répertoire ./content.
Chaque répertoire doit contenir un fichier index.md dont le contenu commence par :
---
title: Titre de ma page
description: La description de ma page
weight: 101
---
## Voici le premier chapitre de ma page
6/ Mettre en place un build
Hugo est un outil de génération et pas un outil de build.
Pour ne pas avoir à retenir les paramètres de ligne de commande à utiliser pour démarrer un serveur local ou générer l’application, il est préférable de stocker les scripts quelque part. Comme un outil de build (Maven ou NPM) est toujours utile, autant en utiliser un. Donc il faut créer un package.json minimal :
{
"name": "monProjet",
"version": "1.0",
"scripts": {
"start": "hugo-0.140.1 serve --bind 0.0.0.0 ",
"build": "hugo-0.140.1.exe"
},
"dependencies": {
}
}
Pour démarrer le serveur, il suffit donc d’exécuter la commande npm run start.
Pour générer le site, il suffit donc d’exécuter la commande npm run build.
7/ Publier dans GitHub
La plus simple des solutions de publication dans Gitbug-Pages est de créer un répertoire ./docs dans la branche principale du dépôt avec le contenu du site.
Or ce répertoire est utilisé, par défaut, par Hugo, pour stocker les pages HTML générés par le serveur local. Il est donc préférable de séparer ce répertoire de génération temporaire (hugo serve) du répertoire de génération réel (hugo).
De plus, la génération ajoute ou modifie les fichiers du répertoire ./docs mais ne supprime rien. Donc il faut que le répertoire soit vidé avant de faire générer les pages HTML à Hugo.
Donc le package.json doit être enrichi :
{
"name": "monProjet",
"version": "1.0",
"scripts": {
"start": "hugo-0.140.1 serve --bind 0.0.0.0 -d docsServe",
"build": "rm -rf ./docs/* && hugo-0.140.1.exe"
},
"dependencies": {
}
}
Création d'un site avec Hugo
La structure
Le plus simple est toujours de partir d’une base de travail simple.
Pour cela, sont disponibles plusieurs base :
- SIMPLE : un site Hugo de 2 pages avec le thème LEARN
- INDUS : le même site SIMPLE mais industrialisé avec NPM pour démarrer le site sur Windows, Unix ou simplement générer le site
- SEARCH : le même site INDUS avec la fonction de recherche basée sur LUNR
- JENKINS : mon site est basé sur SEARCH mais automatiquement publié sur les GitHub:pages
Les astuces à connaître
Hugo en 2 mots
L’idée d’Hugo est de générer un site WEB statique avec une jolie mise en forme sans se prendre la tête avec la mise en forme.
Donc le contenu du site est codé en Markdown et Hugo génère les pages WEB.
L’avantage d’un site statique est qu’il est extrêmement performant. Cette solution est utilisée en production pour générer des pages WEB dont la fréquence de modification des contenus est faible (1 à 2 fois par jour).
Manipulation
Le site se démarre en double-cliquant sur “/bin/startServer.cmd”. Le site est alors disponible sur l’adresse http://localhost:1313.
Toute modification d’une page existante déclenche automatiquement son rafraîchissement dans le navigateur. Mais l’ajout d’une nouvelle page n’est pas pris en compte à chaud. Il faut couper le serveur et le redémarrer.
Les premières lignes de chaque page (les fichiers “.MD” du répertoire “docs”) sont des propriétés :
- title : le titre de la page utilisé dans l’onglet affichant la page mais aussi dans le menu latéral de la page
- prev : [optionnel] le chemin vers la page précédente qui doit toujours commencer et se finir par un “/”. Il est possible de naviguer par le menu mais aussi par les flèches présentes à gauche et à droite des articles ou encore avec les flèches gauche et droite du clavier.
- next : [optionnel] le chemin vers la page suivante
- weight : [optionnel] l’importance de la page et donc son ordre d’apparition dans le menu
- chapter : [optionnel] ’true’ si la page est un chapitre. Le contenu est alors centré par défaut.
Outil utile
Un site avec Hugo utilisant “prev” et “next” contient donc beaucoup de lien. Il faut les vérifier. Pour le faire automatiquement et rapidement, il existe des outils comme “Broken Link Checker”
outil de check des liens
…
Object Mother
Le pattern tel qu’il est défini aujourd’hui
Ce pattern est dédié à la création d’objets de données utilisés dans des tests codés.
Ce pattern se base sur le pattern Factory. Il propose la création d’une classe dont la responsabilité est de créer des objets.
La particularité de ce pattern est que les données créées sont dédiés aux tests.
Extraire le code de création de ces objets améliore la lisibilité des tests (à condition que le nom des méthodes de l’ObjectMother soit explicite).
De plus, le fait d’utiliser systématiquement un jeu de données particulier permet de créer des données “familières”. Par exemple : Jean est un nouvel utilisateur, Arnaud est un utilisateur avec des droits d’administration, …
A l’usage, ces persona (ou leurs pendants quel que soit le type d’objets manipulés : facture, usine, paie, compteur, …) finissent pas être connus de tous les développeurs. Ceci facilite la conception, le développement et la mise au point des tests.
Sources :
Exemples :
Les risques associés à ce pattern
Ce pattern ne doit pas dérivé en anti-pattern “God Class”. Un ObjectMother ne doit pas devenir un composant trop gros ni dépendant de trop d’autres composants.
Pour cela, il suffit de créer un ObjectMother par groupe de données (par exemple : SecuriteObjectMother, FacturationObjectMother, …).
Et pour limiter le volume de code d’un ObjectMother, il suffit de respecter quelques règles :
- pour créer un nouveau jeu de donnée, il faut créer une nouvelle méthode
- chaque méthode créant des données doit utiliser une méthode déjà existante créant un jeu de données plus simple et doit enrichir ce jeu de données
- seul l’ajout ou la modification d’un attribut obligatoire peut donner lieu à la modification d’une méthode existante. Mais attention, cela nécessite de revérifier tous les tests utilisant la méthode modifiée et les méthodes dérivées)
Guide Du Développeur
Le Guide Du Développeur est l’espace de partage d’une équipe. Il contient toutes les informations utiles aux membres de l’équipe.
Chaque question posée par un collaborateur doit donner lieu à un nouveau paragraphe dans le GDD.
Il est inutile d’imposer un guide du développeur. Il faut le proposer et le faire adopter. C’est un outil pour l’équipe construit par l’équipe. Si personne ne le consulte avant de se mettre en quête d’une réponse (sur Internet ou au près d’un leader), alors il est inutile.
Astuces
La première astuce est à destination des Lead (les membres de l’équipe qui ont tout dans la tête). Dès qu’un collaborateur vient vous poser une question, demandez-lui s’il a consulté le GDD. Si ce n’est pas le cas, qu’il retourne à son poste pour vérifier si la réponse n’est pas dans le GDD (même si vous savez que ce n’est pas le cas). Il faut que cela devienne un réflexe pour toute l’équipe. Et quand il reviendra vous poser la question et qu’il aura obtenu sa réponse, dîtes lui d’ajouter un paragraphe dans le GDD !!
Bien souvent, à ce moment-là, le collaborateur vous dit qu’il n’a pas le temps. Pour beaucoup de gens, toutes les tâches sont prioritaires à la documentation (même le café). Mais il est vrai qu’on n’a pas toujours le temps. Pas de soucis, il vous suffit d’un tableau blanc (ou d’un paperBoard). A chaque réponse obtenue, le collaborateur inscrit son prénom ainsi que les mots clefs de sa question et de sa réponse. Charge à lui de remplir le GDD dans un délai raisonnable puis de venir effacer (ou barrer) son nom.
Valoriser les contributeurs est aussi une bonne idée. Bien souvent, le dernier arrivé sur le projet est le principal contributeur. Il est aussi celui qui doit s’approprier le GDD. Un petit mail avec le meilleur contributeur du mois peut aider à faire adopter le GDD.
Question outil, un fichier MS Word sur un serveur FTP est une solution à proscrire car l’édition à plusieurs est impossible et la gestion des versions (avec un cartouche, …) est lourde. Un document partagé dans une bonne GED (Gestion Electronique de Documents) est une solution. Mais le plus simple reste un WIKI ou un site statique généré (comme le présent site avec Hugo). Les fonctions nécessaires sont :
- pas de prise de tête avec la mise en forme
- suivi des modifications et consultation possible de l’historique
- simplicité de déplacement des paragraphes (pour permettre la réorganisation au fur et à mesure que le GDD s’étoffe).
- dans tous les cas :
- l’usage de l’outil doit être simple
- un moteur de recherche doit être présent
- aucun workflow complexe (relecture, validation, …) ne doit freiner l’enrichissement du GDD
Enfin, il n’existe aucun modèle de GDD. Chaque GDD est unique car les préoccupations, les questions et les réponses changent d’un projet à un autre (technologies différentes, clients différents, organisations différentes, équipes différentes). Il est préférable de démarrer avec une simple page faisant office de foire aux questions. Quand la page devient indigeste, il suffit de regrouper les questions par thème puis de les extraire dans des pages différentes. Ainsi le GDD émergera petit à petit.
Idées de sujets à intégrer au GDD :
Ceci n’est pas un menu de GDD mais juste une liste de sujets à traiter sur la plus part des projets ! Votre GDD, vos questions, votre sommaire !!!
-
référence documentaire
- cahier des charges
- dossier(s) d’architecture
- référentiel des exigences
- référentiel des tests
-
exigences
- quel est le niveau de détails des exigences en entrée des développements ?
- quel est le contexte du projet ou de l’application ?
-
test
- quel est contractuellement le niveau de détails et le formalisme à livrer en fin de conception ?
- stratégie de test du projet
- types de tests disponibles
- cas de test devant être validés en fin de développement
- cas de test devant être codés dans un composant de test (avec sa granularité et les outils à utiliser)
-
conception
- résumé de l’architecture technique
- quels sont les impacts de l’AT sur la conception (BI, ERP ou détails trop fins en xNet) ?
- quel est le niveau de détails attendu en fin de conception (peut-être besoin d’être plus précis que le niveau contractuel en fonction du contexte) ?
- quels sont les outils de conception et/ou de modélisation ?
- quels sont les objectifs des modèles (compréhension, communication, …) et quelle est leur durée de vie ?
- règles de conception (programmation défensive, @designByContrat, modularité, …)
- jeu de données de test
-
développement
- règles de nommage
- liste des frameworks disponibles, leur usage et le pointeur sur leur documentation
-
industrialisation
- éléments composant la Gestion de Configuration Logicielle (Git, SVN, HP ALM, Archiva, Jira, …)
- règles d’usage de la GCL (flow GIT/SVN, snapshots dans le repository de binaires, …)
- règles d’usage de l’intégration continue
- organisation des équipes en amont et en aval des développements (Continuous Delivery)
-
environnements
- installation du poste de développement
- liste et paramètres des environnements de test
- liste des environnements du client
Programmation défensive
Lorsqu’un développeur code une nouvelle méthode, il doit savoir s’il fait confiance au code qui fera appel à cette méthode. Ou pas.
- S’il a confiance, il déclarera les conditions d’appels à la méthode dans le contrat de sa méthode (dans la Javadoc de sa méthode, dans le WSDL, ou tout autre support d’échange avec le client) et ne vérifiera pas les valeurs des paramètres dès le début de sa méthode.
- S’il n’a pas confiance, les premières lignes de code de la méthode vérifieront que les valeurs des paramètres sont acceptables.
La seconde option est de la programmation défensive.
Une méthode peut valider les valeurs des paramètres d’entrée. Ce n’est pas une mauvaise chose en soit. Bien au contraire dans le cas de la validation des données lues dans un fichier envoyé par une application tierce. Même s’il existe un contrat définissant le format des données échangées, personne n’a envie d’intégrer des données de mauvaise qualité dans son système.
Mais une question se pose : “doit-on utiliser la programmation défensive partout ?”. L’ajout de code vérifiant chaque paramètre de chaque méthode de chaque composant du système coûte du temps de développement (du code applicatif et des tests associés). De plus chaque ligne de code ajoute potentiellement un bug dans l’application. Et surtout la maintenabilité d’une application décroit avec l’augmentation du volume de code.
Mais il ne faut pas faire l’amalgame entre la programmation défensive et toutes les validations de données. Par exemple, la validation des données d’un formulaire saisies par un être humain est réalisée par une méthode dont c’est l’objectif. Dans ce cas, ce n’est pas de la programmation défensive. Mais, si le service métier appelé après la validation du formulaire vérifie lui aussi une donnée, là, ce sera de la programmation défensive.
Le choix entre programmation défensive et confiance absolue n’est pas du seul ressort du développeur. C’est un choix fait par l’équipe qui prend en compte le type de composant, le type de données, les contraintes techniques, … Cela doit donner lieu à un chapitre dans le guide du développeur.
Références :
Eclipse
Introduction
Eclipse est un IDE, un environnement de développement intégré. A ce titre, il propose un éditeur de texte et des centaines de fonctionnalités autour. Basé sur un système de plugin, il est très extensible et très personnalisable.
Eclipse n’est pas le seul IDE disponible sur le marché. NetBeans, IntelliJ sont d’autres solutions. Mais je ne fournirais pas de comparatif car je n’ai que très peu utilisé NetBeans et jamais utilisé IntelliJ. C’est une bêtise (je le sais) car il est toujours intéressant de découvrir un nouvel outil pour voir s’il n’est pas meilleur sur certains points.
Un outil mal/sous utilisé
Mais quel que soit l’outil, une fois choisi, encore faut-il savoir s’en servir !
Si vous utilisez un IDE à la place de MS WordPad, il doit y avoir une raison !
- Alors cessez de taper chaque lettre de chaque mot de votre code et utilisez l’auto-complétion !
- Plus de mise en forme du code avec des séries frénétiques de coups sur la barre d’espace et utilisez le formateur automatique !
- Ne recherchez pas un fichier dans l’arborescence mais utilisez le formulaire de recherche !
- Ne compter pas le nombre de ligne depuis le début du fichier mais utiliser le GoToLine (cf. raccourcis plus bas) !
(Ces illustrations ne sont pas le fruit de mon imagination mais viennent de mes observations durant les formations Java que j’ai dispensées en 2016 et 2017 auprès de jeunes développeurs)
A plusieurs occasions, cette question m’a été posée “Comment apprendre à utiliser pleinement Eclipse ?”.
Ma première réponse était de prendre 30 à 45 minutes pour parcourir les nombreux formulaires de paramétrage d’Eclipse pour découvrir toutes les fonctions que l’outil propose :
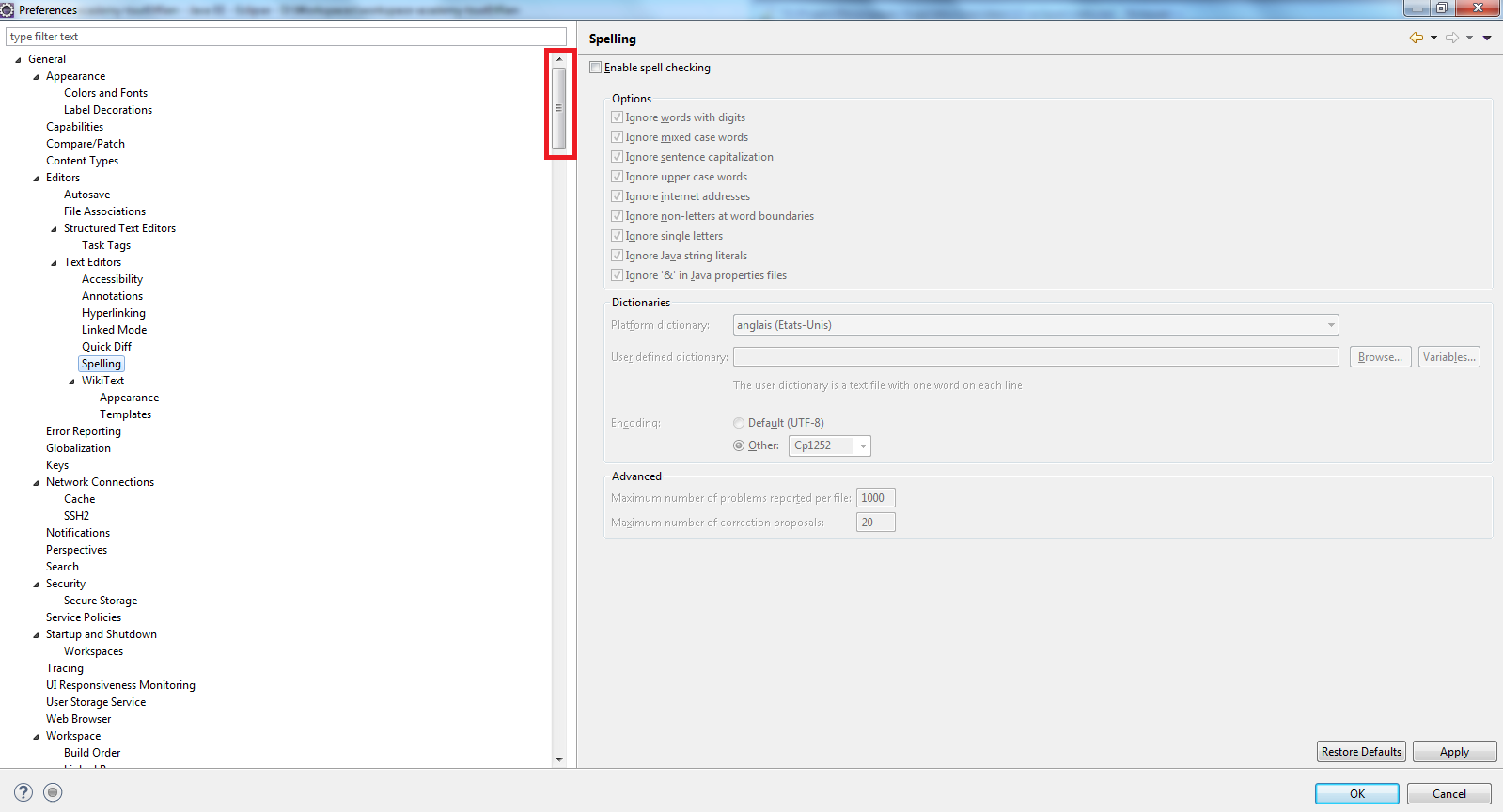
Oui, en effet, il existe un très grand nombre de formulaires de paramétrage. Non, vous n’utiliserez certainement jamais toutes les fonctionnalités de l’outil mais il faut en connaître un minimum.
Dernièrement (en mai 2017), un collègue m’a fait découvrir MouseFeed. Ce plugin d’Eclipse, au clic sur un bouton ou un menu contextuel, affiche quelques instants le raccourci clavier
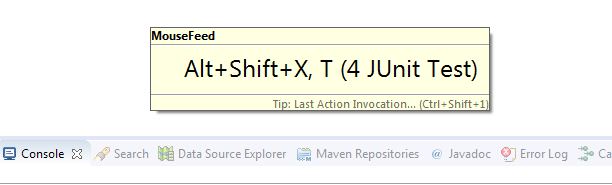
Les raccourcis à connaître
Le minimum du minimum :
- Dans Eclipse en général :
- Shift + Ctrl + T pour la recherche d’une classe (d’un Type)
- Shift + Ctrl + R pour la recherche d’un fichier quel que soit son extension (d’une Ressource)
- Dans un éditeur de code Java
- F3 pour se déplacer à la déclaration d’une variable, d’un paramètre, d’une méthode ou d’une classe
- Ctrl + O (la lettre) pour afficher une popup listant les membres et méthodes et permettant de se déplacer rapidement
- Ctrl + L pour se déplacer à un numéro de ligne dans le fichier (GoToLine)
- Shift + Ctrl + S pour sauvegarder tous les fichiers ouverts et en cours de modification
- Les raccourcis à oublier grâce aux SaveActions (cf. plus bas) :
- Shift + Ctrl + F pour le formatage des sources
- Shift + Ctrl + F pour la réorganisation des imports
- Les raccourcis avancés :
- Shift + Ctrl + X pour exécuter la classe en cours de modification (raccourci à faire suivre du type d’exécution T pour JUnit, N pour TestNG, …)
- F4 pour afficher la hiérarchie d’une classe
- Shift + Ctrl + G pour rechercher les utilisations d’une méthode
Les fonctionnalités natives indispensables
La première à configurer : le formateur de code car chaque client/projet a ses contraintes. Et le formatage ne doit pas être fait à la main !!!!!!!
La plus belle des fonctionnalités natives d’Eclipse se nomme “Save Actions”.
Son but : à chaque sauvegarde d’une classe Java, il exécute un certain nombre d’action telle que :
- le formatage des sources
- la réorganisation des imports
- le tri des membres et méthodes (ordre configurable)
- la suppression des espaces/tabulations dans les lignes vides
- l’ajout du mot clef final systématique (configurable)
- l’ajout du mot clef this systématique (configurable)
Les plugins très utiles en fonction des projets
Le plugin JBoss Tools contient les Hibernate Tools.
Ce plugin permet de configurer un éditeur de requête HQL lié à une base de données et une configuration JPA (ou Hibernate) et permet l’exécution et le débogage de requêtes.
(cf. billet décrivant l’usage de ce plugin)
Pipeline
Définition de l’Intégration Continue (IC dans la suite du chapitre)
En une seule phrase
L’intégration continue a pour objectif de valider que le code actuellement présent dans le repository de source est valide.
La fréquence de la validation et même la définition de cette validation sont très variables d’un projet à un autre :
- la fréquence peut être :
- 1 fois par jour (minimum du minimum)
- 2 fois par jour (à 13h et à 23h par exemple)
- quelques fois par jour (toutes les 2 heures par exemple)
- à chaque commit (solution optimum)
- la validation peut comprendre :
- la compilation et le packaging de la solution (minimum du minimum)
- l’exécution des tests (unitaire & de développement & intégration & bout en bout & non régression)
- l’analyse de la qualité du code (Sonar par exemple)
- les tests de performance (non pas pour valider les exigences de performance ou robustesse mais pour valider que les temps d’exécution des fonctionnalités importantes ne se dégradent pas pour un jeu de données et une plateforme donnée)
- les tests de sécurité (lister les failles potentielles à partir des dépendances de la solution)
Pourquoi ? Pour qui ?
L’erreur est humaine. Un développeur peut, par inadvertance et très rarement (bien entendu), pousser sur le repository du code invalide (qui ne compile pas ou qui casse des tests).
A cet instant-là, le projet n’est plus en mesure de livrer la solution. Ce qui est très gênant pour les projets en MCO dont le délai de livraison d’un correctif n’est que de quelques heures. Et surtout les autres développeurs de l’équipe ne peuvent plus récupérer les modifications poussées sur le repository.
Il faut donc corriger cette situation au plus vite. Mais encore faut-il détecter le problème. L’Intégration Continue est là pour ça !!
Les actions à faire réaliser par l’IC
Si l’IC est capable d’exécuter des tests d’intégration voire des tests de bout en bout, elle est donc capable de déployer la solution sur un environnement. Pourquoi ne pas utiliser ce script/outil pour mettre à disposition des testeurs un bouton déclenchant un déploiement de la dernière version du code valide sur l’environnement de test de leur choix ?
Si l’IC peut déclencher n’importe quel script/outil, pourquoi ne pas automatiser les tâches récurrentes et pénibles comme le déplacement des livrables sur le serveur FTP du client ou l’extraction de la liste des bugs corrigés dans une version de la solution ou extraire la liste des commits ou même générer un bon de livraison ?
Bon, arrivé à ce point, qu’a-t-on :
- pour les développeurs, l’IC vérifie régulièrement la validité du code
- pour les testeurs, l’IC déploie une version de la solution sur l’environnement de leur choix
- pour le responsable de la livraison, l’IC prépare tous les livrables (ou une grande partie)
Mais les analystes fonctionnels, les développeurs et les testeurs ont des interactions plus importantes que ça !
- un analyste ne peut-il pas informer les développeurs que son(ses) exigence(s) sont prêtes à être développées (cf. Definition Of Ready) ?
- un développeur ne peut-il pas prévenir un autre développeur que son code est prêt à être relu/revu ?
- un relecteur ne peut-il pas informer un testeur qu’une (ou plusieurs) exigence(s) est (sont) terminées (cf. Definition Of Done) et prête(s) à être qualifiée(s) ?
- un testeur ne peut-il informer le responsable des versions qu’une (ou plusieurs) exigence(s) est(sont) testée(s) ?
Et pourtant, le référentiel des exigences existe certainement (HP ALM par exemple), le référentiel des tests existe aussi (encore HP ALM par exemple) et l’outil de revu/relecture de code est installé. Il est certainement possible de lier tout ce petit monde.
Définition du Continuous Delivery
Une fois tous les membres de l’équipe outillés, il est possible de décrire le processus de production de l’équipe par un tuyau dans lequel entre une (ou un petit groupe d’) exigence(s) qui enchaîneront une série d’étapes jusqu’à être terminées.
Ce processus dépend totalement de l’équipe mais commence toujours avec une exigence (ou un petit paquet). Donc la première étape est toujours la description de cette (ces) exigence(s). Peuvent suivre, la conception détaillée, le développement, la qualification interne, la recette client, le déploiement en pré-production puis celui en production.
Certaines équipes vont y ajouter de la relecture de code ou des revues de conception ou arrêter leur pipeline à la livraison de leur client (s’ils ne gèrent pas ni la recette ni la production).
Et enfin, chaque exigence ne donnant pas lieu à une mise en production, s’ajouteront des étapes conditionnées par une promotion manuelle : une action manuelle qui autorisera une instance du pipeline à avancer.
Voici un exemple de Pipeline très simple et très singulier : le pipeline de mon projet personnel ‘Mariage’

Qualimétrie
La Qualimétrie est la mesure de la qualité d’un projet.
Le problème qui se pose avant de parler de qualimétrie.
Or, qualité veut tout et rien dire. Donc, ici, je vais me limiter à la qualité du code.
Mais pour évaluer le code d’un projet, encore faut-il qu’il existe des règles de conception/développement sur le projet. Sans règle, il ne peut y avoir de qualité.
Et oubliez l’expression “les standards de qualité” !!! Vous en voulez des standards ? On prend les règles de développement de SUN ? Ou celles d’Eclipse ? Ou les règles de nommage de la convention JavaBean ? Ou celles du client (s’il en a défini et qu’elles ne sont pas obsolètes) ?
Donc, par pitié, que chaque projet définisse ses règles ! En s’appuyant sur des éléments existants bien entendu et sans redécouvrir la roue !
A partir de là, on peut commencer à mesurer la qualité du code.
Pourquoi faire
“La qualité ne sert à rien.” Si vous le pensez, quittez ce site !
Vous continuez à lire. Tant mieux. Désolé de paraître dur mais il n’est pas acceptable d’ignorer la qualité d’un projet.
Elle peut ne pas être prioritaire. Mais ça se paiera tôt ou tard.
Pourquoi ? Car un code moche est un code compliqué à faire évoluer !
Les développeurs prendront des raccourcis et feront du code moche car le code est déjà moche et que tout le monde le sait et s’en moque. Et du moche dans du moche, au milieu du moche, … donnera un code incompréhensible, incohérent et très difficile à maintenir.
Ce jour-là, apparaîtront des bugs en pagaille et les corrections prendront de plus en plus de temps.
Que comprend la qualimétrie de code
Les règles de conception/développement portent sur beaucoup d’aspects du code. Donc la qualimétrie aussi :
- format du code :
- longueur des lignes de code,
- longueur des lignes de commentaire,
- nombre de lignes maximal d’une méthode,
- nombre de lignes maximal d’une classe,
- tabulation en espace ou non,
- indentation
- …
- lisibilité et compréhensibilité du code :
- longueur des noms de variables/paramètres/membres/méthodes/classes/interfaces/package,
- mauvais usages des noms réservés (i, j, T, …)
- …
- complexité des algorithmes :
- nombre maximal de boucles imbriquées,
- méthodes récursives,
- mauvais usages de mots clefs (return, break, continue, …)
- …
- couverture de code
- pourcentage de lignes de code testées
- pourcentage de combinaisons de conditions (if, while, …) testées
- sécurité
- duplication
- …
Quels outils
L’outil le plus connu est SonarQube.
Ce n’est pas à proprement parlé un outil de qualimétrie. C’est un portail de restitution et agrégation des violations détectées par d’autres outils comme Checkstyle, FindBugs, PMD, CPD, Clover, Cobertura, … De plus, SonarQube permet d’administrer le paramétrage de ces analyseurs et d’exécuter les analyses.
C’est donc un outil très complet et indispensable !
SonarQube propose une plateforme en ligne, gratuite et publique pour les projets Open Source.
Que votre projet démarre tout juste, ou que vous ayez déjà des milliers de lignes de code, il est toujours temps de commencer à mesurer la qualité.
Le premier objectif de la mesure est de faire un point. Est-ce une catastrophe ? Ou pas ? Attention, il faut que le paramétrage des outils d’analyse corresponde à vos règles !! Si vous prenez le paramétrage par défaut de SUN sur votre projet sans l’adapter à votre contexte, vous obtiendrez des milliers de violations.
Vous avez votre première mesure ? Très bien ! Première chose à faire, que la dette soit petite ou grande, ne pas la dégrader ! Surveiller les violations et, à chaque nouveau problème détecté, trouvez le développeur, apprenez/rappelez lui les règles du projet et faites-lui corriger sa coquille.
Une fois toute hémorragie contenue, on peut s’attaquer à réduire les violations. Il existe plusieurs stratégies et deux d’entre elles me semblent pertinentes à mener en parallèle :
- trouver, quel que soit leur sévérité, les violations les plus nombreuses mais corrigibles en quelques minutes (avec un outil ou un rechercher/remplacer d’expression régulière)
- avantages : diminuer le nombre de violations rapidement et simplement
- soucis : les développeurs risquent d’en recréer car la correction est un bon moyen d’apprendre
- faire corriger, chaque semaine, par chaque développeur, un petit lot de violations parmi les plus importantes
- avantages : les violations diminueront régulièrement, les développeurs apprendront durant les corrections, le temps passé à améliorer le code sera réparti sur plusieurs personnes et plusieurs semaines
- soucis : la qualité augmentera lentement (à condition qu’aucune hémorragie ne subsiste), une personne aura la charge d’analyser les rapports SonarQube pour lister les violations à traiter chaque semaine
Les travers et excès
La mesure de la qualité doit être une aide. Pas un frein !
- Il faut analyser et extraire uniquement les problèmes violant les règles du projet (et uniquement elles) ;
- SonarQube n’est pas un outil de surveillance de la production des développeurs : la découverte d’une violation ne doit pas donner lieu à un lynchage public ;
- L’outil est au service de l’équipe et non d’un râleur prenant plaisir à critiquer le travail des autres.
Mieux que surveiller, prévenir !
SonarQube analyse le code présent sur le serveur hébergeant les sources.
Mais, le mieux serait qu’un outil prévienne le développeur dès qu’il code une bêtise !
La réponse : SonarLint ! Cet outil (sous forme de plugin dans les IDE) se connecte à SonarQube, télécharge les règles de validation et vérifie le code directement dans l’environnement du développeur.
Avec cet outil, si un développeur crée encore des violations, c’est qu’il se moque de son équipe. Là, très chères collègues, je vous laisse lui expliquer votre point de vue entre gens courtois et polis (dans la mesure du possible ;) ).
JS
Quelques notes sur les incontournables choses à connaître en JS.
Au sommaire :
Les 6 falsies
- false
- 0
- ’’ ou "" string de length 0
- NaN
- undefined
- null
Astuce :
- !!maVariable permet de récupérer un booleen TRUE si la valeur de la variable n’est pas l’un des falsies
- a && b renvoie a s’il est un falsie et b sinon
- a || b renvoie a s’il n’est pas un falsie et b sinon
Les paramètres par défaut
function toto(a = 1, b = 2) { return a * b; }
Les déclarations de variables
- const permet la déclaration d’une variable non ré-affectable (le final de Java)
- let permet de déclarer une variable dans un scope précis (sans écraser une variable du même nom dans le scope parent)
- var est et reste la déclaration de variables de l’époque mais ne devrait plus être utilisé.
une belle explication ici
Déclaration des scripts dans une page HTML
Un JS ne doit pas être déclaré dans le head mais à la fin du body (source 1, source2).
Au pire, si le JS ne dépend d’aucun autre, il peut être chargé avec ASYNC. Mais attention aux dépendances entre scripts d’une même page (source).
Les exceptions en JS
He oui, ça existe. Mais c’est pénalisant en performance. Donc à utiliser avec modération.
try {
throw {"name":"monException", "message":"momMessage"};
} catch (e) {
}
Déclarer une classe
solution 1 : la fonction
function MaClasse(args){
this.prop = args;
this.maMethode = function() {
alert(this.prop);
};
}
var monInstance = new MaClasse(true, "bonjour");
monInstance.maMethode();
solution 2 : la description
let monInstance = {
prop: args,
maMethode: function() {
alert(this.prop);
}
}
solution 3 : le prototype
function MaClasse(args){ ... }
MaClasse.prototype.prop = ...;
MaClasse.prototype.maMethode = function() { alert(this.prop); };
var monInstance = new MaClasse(true, "bonjour");
monInstance.maMethode();
solution 4 : l’héritage
// Type Rectangle avec une largeur et une longueur
function Rectangle(largeur, longueur) { this.largeur = largeur; this.longueur = longueur; };
Rectangle.prototype.largeur = 0;
Rectangle.prototype.longueur = 0;
Rectangle.prototype.calculSurface = function() { return this.largeur * this.longueur; };
// Type Carre avec une largeur (la longueur et la largeur sont égales)
function Carre(largeur) { Rectangle.call(this, largeur, largeur); };
Carre.prototype = Object.create(Rectangle.prototype);
Carre.prototype.constructor = Carre;
// Test du Rectangle
let monRec = new Rectangle(3, 10);
let surfaceMonRec = monRec.calculSurface(); //30
// Test du Carre
let monCarre = new Carre(5);
let surfaceMonCarre = monCarre.calculSurface(); //25
Utiliser des getter / setter en JS
let monInstance = {
get prop() {
return ...;
}
set prop(value) {
...
}
}
Si le getter n’existe pas, la valeur retournée est undefined
Déclarer un module encapsulant du code
var MonModule = ( function() {
// privé
const compteur = 18;
function maMethodePrivee() {
...
}
// public
let module = {};
module.methodePublique = function() {
...
}
return module;
})();
Installation d'un serveur pour une Integration Continue
Création de la machine :
Créer une machine de type small chez Amazon EC2 avec l’OS Ubuntu xx.xx de votre choix.
Dans le groupe de sécurité, ouvrir les ports HTTP HTTPS SSH (ouverts à tous)
Se connecter en SSH et exécuter
sudo apt-get update
sudo apt-get -y upgrade
Installation de Java et Jenkins :
sudo apt-get -y install default-jdk
@see https://www.jenkins.io/doc/book/installing/linux/#weekly-release
wget -q -O - https://pkg.jenkins.io/debian/jenkins.io.key | sudo apt-key add -
sudo sh -c 'echo deb https://pkg.jenkins.io/debian binary/ > /etc/apt/sources.list.d/jenkins.list'
sudo apt-get update
sudo apt-get -y install jenkins
Pour définir le rootContext de Jenkins, exécuter sudo vi /etc/default/jenkins et modifier la dernière ligne pour ajouter “–prefix=$PREFIX” (attention au double tirets)
Pour prendre en compte la modification, redémarrer Jenkins
Installation apache2
sudo apt-get -y install apache2
sudo a2enmod proxy proxy_http
sudo a2enmod headers
sudo a2enmod ssl
Créer le fichier sudo vi /etc/apache2/sites-available/monHttp.conf
<VirtualHost *:80>
ServerAdmin webmaster@localhost
ServerName me.guillaumetalbot.com
ServerAlias ci
</VirtualHost>
sudo a2ensite monHttp
sudo /etc/init.d/apache2 restart
Installation LetsEncrypt
@see https://certbot.eff.org/instructions et sélectionner Apache et le bon OS
Penser à configurer le nom de domaine pour pointer sur la machine auprès du DNS avant
sudo snap install core; sudo snap refresh core
sudo snap install --classic certbot
sudo ln -s /snap/bin/certbot /usr/bin/certbot
sudo certbot --apache
Modifier le fichier sudo vi /etc/apache2/conf-available/security.conf et changer les valeurs :
- ServerTokens Prod
- ServerSignature Off
Activer les accès sécurisés aux outils :
Modifier le fichier sudo vi /etc/apache2/sites-available/monHttp-le-ssl.conf et y ajouter
DocumentRoot /var/www/html
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
ProxyRequests Off
ProxyVia Off
<Proxy *>
Order deny,allow
Allow from all
</Proxy>
ProxyPreserveHost on
ProxyPass /jenkins http://localhost:8080/jenkins nocanon
ProxyPassReverse /jenkins http://locahost:8080/jenkins
ProxyPassReverse /jenkins http://me.guillaumetalbot.com/jenkins
RequestHeader set X-Forwarded-Proto "https"
RequestHeader set X-Forwarded-Port "443"
AllowEncodedSlashes NoDecode
<IfModule mod_headers.c>
Header set X-Content-Type-Options nosniff
Header set X-Permitted-Cross-Domain-Policies "none"
# pour ne pas bloquer Jenkins
# Header set Content-Security-Policy "child-src 'none'; object-src 'none'"
# Header set X-Frame-Options DENY
Header set X-XSS-Protection "1; mode=block;"
Header set Strict-Transport-Security "max-age=300; includeSubDomains; preload; always;"
Header set Public-Key-Pins "pin-sha256=\"base64+primary==\"; pin-sha256=\"base64+backup==\"; max-age=5184000; includeSubDomains"
</IfModule>
Puis exécuter :
sudo /etc/init.d/apache2 restart
sudo rm /var/www/html/index.html
Créer le fichier sudo vi /var/www/html/index.html avec le contenu suivant :
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta http-equiv="refresh" content="3; url=https://talbotgui.github.io" />
</head>
<body>
Redirection en cours...
</body>
</html>
Configuration Jenkins :
Aller à l’adresse https://…../jenkins et suivre les instructions
Installation email :
sudo apt-get install postfix
me.guillaumetalbot.com
sudo vi /etc/postfix/main.cf
myhostname = me.guillaumetalbot.com
sudo service postfix restart
Installation Maven :
sudo mkdir /usr/share/m2repo
sudo chmod a+rw /usr/share/m2repo
sudo apt-get -y install maven
Modifier le fichier sudo vi /usr/share/maven/conf/settings.xml pour définir le repo local
Installation NPM & NodeJS
Vérifier la dernière version disponible du setup et remplacer les YY (version 14 en aout 2021).
curl -sL https://deb.nodesource.com/setup_YY.x | sudo -E bash -
sudo apt-get install -y nodejs
Pour paramétrer Jenkins avec une configuration de base
Premier accès et paramétrage de base
- accéder au portail pour la première fois
- suivre les instructions pour se connecter en tant qu’administrateur
- sélectionner l’installation des plugins courants
Installer les plugins nécessaires
- accéder à la partie “administrer Jenkins” puis “gestion des plugins”
- dans la liste des plugins disponibles, sélectionner “blue ocean” et cliquer sur “installer sans redémarrer”
- dans la liste des plugins disponibles, sélectionner “Pipeline Utility Steps” et cliquer sur “installer sans redémarrer”
- une fois les plugins installés, cliquer sur la case “redémarrer Jenkins” et patienter que Jenkins redémarre
Déclarer les outils
- accéder à la partie “administrer Jenkins” puis “Configuration globale des outils”
- cliquer sur “Ajouter JDK”, décocher “installation automatique”, saisir “java local” et “/usr/lib/jvm/java-11-openjdk-amd64/”
- cliquer sur “Ajouter Maven”, décocher “installation automatique”, saisir “M3” et “/usr/share/maven/”
Déclarer les clefs
- faire le tour de tous vos dépôts et jenkinsFile pour lister les clefs nécessaires à leur bon fonctionnement
- accéder à la partie “administrer Jenkins” puis “Manage credentials”
- cliquer sur “Jenkins” puis “identifiants globaux”
- cliquer sur “Ajouter identifiant” et saisir les élements nécessaires
Publication d’application
Si votre serveur héberge aussi des applications déployées automatiquement depuis votre Jenkins
- faire le tour de tous vos dépôts et jenkinsFile pour lister les clefs nécessaires à leur bon fonctionnement
- exécuter autant de fois que nécessaire les commandes suivantes
sudo mkdir /var/www/html/xxx
sudo chmod a+rw /var/www/html/xxx
Si la machine est de type tiny
La machine va manquer de RAM. Pour ajouter une partition de SWAP (dans un fichier) (http://tecadmin.net/add-swap-partition-on-ec2-linux-instance/)
sudo dd if=/dev/zero of=/var/myswap bs=1M count=2048
sudo mkswap /var/myswap
sudo swapon /var/myswap
sudo chmod 0644 /var/myswap
Petits outils à installer
Parmis les outils utiles dans les scripts SHELL, il faut bien souvent installer
sudo apt-get -y install zip
Les répertoires à vider pour récupérer de l’espace :
/var/lib/jenkins/.npm/_logs/
Notes sur l’installation d’un Archiva
Ressources :
Installation :
- extraire le contenu de l’archive
- si Java9 est le JDK par défaut, modifier le fichier conf/wrapper.conf :
wrapper.java.command=C:/Program Files/Java/jdk1.8.0_151/bin/java
- sous Windows, dans un interpréteur de commande en mode “Admin”, exécuter
archiva install puis archiva start
- Archiva sera disponible à l’adresse http://localhost:8080/
Petites commandes pratiques pour entretenir le serveur :
Pour rechercher les répertoires prenant de la place : sudo du -cha --max-depth=1 / | grep -E "[0-9]M|[0-9]G"
Et un petit script permettant de faire le ménage régulièrement :
apt clean all
rm /var/log/**/*.gz
rm /var/log/journal/*/*-00000*.journal
rm -rf /var/lib/jenkins/workspace/*
rm -rf /var/lib/jenkins/.sonar/*
rm -rf /var/lib/jenkins/.m2/*
rm -rf /var/lib/jenkins/.npm/*
Installation du Cloud SDK
Installation :
export CLOUD_SDK_REPO="cloud-sdk-$(lsb_release -c -s)"
echo "deb http://packages.cloud.google.com/apt $CLOUD_SDK_REPO main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
sudo apt-get update && sudo apt-get install google-cloud-sdk
Connexion :
- créer une clef depuis la console GCloud (IAM / comptes de service)
- activer les APIs “Cloud Resource Manager API” et “App Engine Admin API” depuis la console GCloud (API / Bibliotheque)
- déposer le fichier JSON sur le serveur
- se connecter une première fois avec
gcloud auth activate-service-account --key-file=LE_FICHIER_JSON
- exécuter la commande
gcloud init et renseigner toutes les informations
Licence
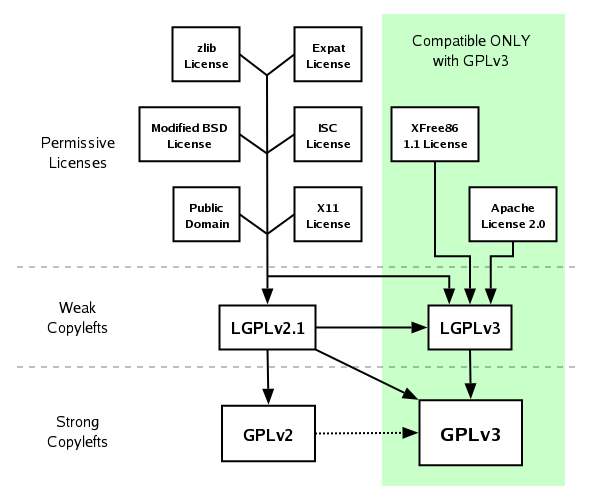
Source : https://opensource.stackexchange.com/questions/21/whats-the-difference-between-permissive-and-copyleft-licenses
Git
1/ Les basics :
Pour cloner un dépot : git clone https://xxxxxxxxx
Pour ajouter une modification : git add rep1/monFichier.xxx
Pour ajouter toutes les modifications : git add -A
Pour annuler les ADD : git reset
Pour annuler le ADD d’un fichier : git reset rep1/monFichier.xxx
Pour annuler les modifications d’un fichier : git checkout rep1/monFichier.xxx
Pour commiter : git commit -m "mon message"
Pour commiter les fichiers modifiés (pas les ajouts) sans faire de ADD : git commit -am "mon message"
Pour pousser ces commits sur le repository : git push
Pour récupérer toutes les modifications réalisées depuis le dernier PULL : git pullou git pull --rebasesi des commits ont été réalisés depuis le dernier PULL
En cas de problème durant un rebase, la commande git rebase --abortannule tout.
2/ Les utilitaires :
Pour voir le statut du dépot local : git status
Pour voir les modifications d’un fichier : git diff rep1/monFichier.xxx
Pour voir toutes les modifications : git diff
Pour obtenir les logs : git logou git log --pretty=oneline
Pour afficher les informations du repository distant : git remote show origin
Pour sauvegarder dans un espace temporaire des modifications (sans les commiter) : git stash
Pour lister les sauvegardes : git stash list
Pour récupérer la sauvegarde la plus récente : git stash pop
Pour annuler tous les commits locaux : git reset HEAD^
3/ La manipulation d’historique
3.1/ squash & rename :
Pour modifier l’historique sur les 5 derniers commits (à ne faire que si aucun push n’a été fait depuis) : git rebase --interactive HEAD~5
Dans l’éditeur qui s’ouvre, remplacer les pick par :
- r pour reword afin de modifier le message du commit (le nouveau message est à saisir après avoir sauvegarder ce premier éditeur de texte)
- s pour squash permet de fusionner le commit avec celui qui le précède dans le temps (et fusionne les commentaires des deux commits)
- f pour fixup qui fusionne comme le squash mais qui supprime le commentaire
Pour pousser sur le repository distant un rebase qui modifie l’historique déjà poussé /!\ attention quand on travaille en équipe /!\ : git push --force
3.2/ La manipulation d’historique - author :
Pour modifier l’auteur des commits d’un dépôt, il est possible d’utiliser la commande suivante :
git filter-branch -f --env-filter "
GIT_AUTHOR_NAME='Guillaume TALBOT'
GIT_AUTHOR_EMAIL='talbotgui@gmail.com'
GIT_COMMITTER_NAME='Guillaume TALBOT'
GIT_COMMITTER_EMAIL='talbotgui@gmail.com'
" HEAD
Mais, ensuite, il ne faut pas oublier de modifier l’auteur dans le dépôt (pour ne pas recommencer la même erreur) :
git config user.name "Guillaume TALBOT"
git config user.email "talbotgui@gmail.com"
4/ La manipulation de branches :
Pour lister les branches locales : git branch
Pour passer d’une branche à l’autre : git checkout maBranche
Pour créer et passer à une autre branche : git checkout -b maBranche
Pour supprimer une branche : git branch -d maBranche
Pour afficher les différences entre deux branches : git dif maBranche...lAutreBranche
Pour fusionner simplement une branche vers la branche courante : git merge monAutreBranche
Pour pousser dans le master les modifications d’une autre branche en un seul commit :
git checkout master
git merge --no-ff maBrancheFeature
Pour pousser sur le dépot distant toutes les branches : git push --all
Pour lier une branche locale à une branche distante existante (après avoir fait un push -all créant une branche par exemple) : git branch --set-upstream-to origin/maBranche
5/ Ajouter un outil de DIFF pour les documents Microsoft Office
- Ajouter les lignes suivantes dans le fichier .gitconfig (vi ~/.gitconfig depuis une console gitbash) :
[diff]
tool = pdiff
[difftool "pdiff"]
cmd="wscript.exe \"c:\\Program Files\\TortoiseSVN\\Diff-Scripts\\diff-ppt.js\" \"`pwd`/$REMOTE\" \"$LOCAL\""
- Pour tester, exécuter la commande :
git difftool -Y -t pdiff maPresentation.pptx
- Ajouter un alias pour appeler ce diff (dans la liste des alias existante si besoin) :
[alias]
diffP = difftool -Y -t pdiff
- Pour tester cet alias :
git diffP maPresentation.pptx
6/ Ajouter deux scripts (avec alias) pour activer/désactiver un proxy
- Placer le script suivant dans le script setGitConfigProxy.sh dans le répertoire d’installation de GIT
git config --global http.proxy http://mon.proxy:8080
git config --global https.proxy https://mon.proxy:8080
- Placer le script suivant dans le script unsetGitConfigProxy.sh dans le répertoire d’installation de GIT
git config --global --unset http.proxy
git config --global --unset https.proxy
- Exécuter les commandes suivantes :
git config --global alias.setProxy '!sh $GIT_EXEC_PATH/../../../setGitConfigProxy.sh'
git config --global alias.unsetProxy '!sh $GIT_EXEC_PATH/../../../unsetGitConfigProxy.sh'
- Pour manipuler le proxy pour NPM et MAVEN depuis ces scripts, il suffit d’ajouter les lignes suivantes :
# setGitConfigProxy.sh
# Proxy pour GIT
git config --global --unset http.proxy
git config --global --unset https.proxy
# Proxy pour NPM
npm config rm proxy
npm config rm https-proxy
# Proxy pour MAVEN
sed "s/active>true/active>false/" -i C:/outils/apache-maven-3.5.2/conf/settings.xml```
# unsetGitConfigProxy.sh
# Proxy pour GIT
git config --global http.proxy https://mon.proxy:8080
git config --global https.proxy https://mon.proxy:8080
# Proxy pour NPM
npm config set proxy https://mon.proxy:8080
npm config set https-proxy https://mon.proxy:8080
# Proxy pour MAVEN
sed "s/active>false/active>true/" -i C:/outils/apache-maven-3.5.2/conf/settings.xml
7/ Articles utiles :
les différents FLOW avec Git
Modèle 1 : a-successful-git-branching-model
sources :
Liste des branches :
- master => la branche déployable en production à tout instant
- develop => la branche contenant tous les développements réalisés pour la prochaine release
- feature_XX => la branche contenant les commits d’une fonctionnalités
- initialisée depuis : DEVELOP
- peut être mergée dans : DEVELOP
- release_XX => la branche qui contient les commits d’une version précise de l’application
Règles à respecter :
- master :
- tout commit sur le MASTER donne lieu à un tag et un déploiement en production
- develop :
- tout développement terminé doit être mergé sur la branche DEVELOP
- feature_XX :
- à créer depuis DEVELOP
- à merger dans DEVELOP
- à ne jamais pousser sur le repository ORIGIN
- les développeurs peuvent se synchroniser entre eux pour travailler sur une même feature
- ne pousser dans DEVELOP que quand la fonctionnalité est terminée et souhaitée pour la prochaine version (car la branche de la prochaine version sera créée depuis DEVELOP)
- release_XX :
- à créer depuis DEVELOP
- à merger dans DEVELOP et MASTER
- quand la plus part des fonctionnalités (voire toutes) ont été intégrées dans DEVELOP, on créer la branche release_XX
- quand la release est terminée et validée, la branche est poussées dans MASTER (pour livraison) et dans DEVELOP (pour y mettre les correctifs)
- toute correction d’une fonctionnalité doit être faite sur la branche release_XX
- hotFix_XX :
- à créer depuis MASTER
- à merger dans DEVELOP et MASTER
- si un bug bloquant survient, il est corrigé dans une branche hotFix_XX
- une fois le bug corrigé, la branche hotFix_XX est poussée dans MASTER et DEVELOP
Avantages et problèmes :
- ~ flow complexe mais un outil existe pour en simplifier l’usage (cf. paragraphe suivant)
-
- comment vérifier à chaque instant que les branches feature_XX sont intégrables sans conflit ni régression (chacune avec DEVELOP et toutes les combinaisons de feature_XX avec DEVELOP) ?
-
- permet des relectures de code facilement directement sur la branche feature_XX avant son intégration dans DEVELOP
-
- habituellement, MASTER est la branche centrale d’un dépot. Autant renommer DEVELOP en MASTER et la notion de MASTER dans ce flow n’apporte rien car chaque commit dans MASTER donne lieu à une branche release_XX
- ~ qu’entend-on par feature ? Si une branche feature_XX a une durée de moins de 5 jours et qu’on démarre 4-5 branches le même jour (au début du sprint), les conflits risquent de poser problèmes.
-
- ce modèle part du principe qu’il n’existe qu’une version finale à une instant T (le master). Or, dans une prestation de développement d’application par une SSII chez un client, l’équipe gère une version en qualification interne, une en recette client et une en production (modèle un peu ancien mais encore très vivant). Exemple : On a une version 1.0.3 en production et une 1.1 en “recette client”. Donc le master est à l’image de la 1.1. Comment créer un patch sur la vielle version ???
Modèle 1 : Git Flow, l’outil qui va avec
sources :
Pour simplifier l’usage de ce modèle, GitFlow propose de nouvelles commandes qui font les merges, les créations de branche et les cheryPick :
- sur le même modèle que la console GIT, GitFlow permet d’initialiser un repos et notamment de nommer toutes les branches du modèle :
ssh git flow init
- pour créer et terminer une feature_XX :
ssh git flow feature start maFonctionnalité et ssh git flow feature finish maFonctionnalité
- pour créer et terminer une release :
ssh git flow release start 0.1.0 et ssh git flow release finish 0.1.0
Pour traiter le problème “multi-version” du modèle, gitFlow propose une fonction ssh git flow support. Mais la gestion des cherryPick des bugFixes est à faire manuellement !
Avantages et problèmes :
-
- l’outil simplifie beaucoup l’usage du modèle
-
- L’usage de la fonction
ssh git flow hotfix start est impossible (au risque de livrer la 1.1 en production directement).
Modèle 2 :
source :
Liste des branches :
- master => la branche qui accueille tous les commit de développement
- release_XX => une branche par livraison
- branchesLocales => des branches que créent les développeurs mais qu’ils ne partagent jamais sur ORIGIN
Règles à respecter :
- master :
- tout les développements sont commités dans le MASTER
- release_XX :
- la branche release_XX est créée au moment de la livraison de l’application (en même temps que le tag)
- toute correction d’un bug bloquant se fait sur la branche release_XX
- toute correction d’un bug bloquant donne lieu à un CHERRY PICK vers le MASTER
- branchesLocales :
- les branches locales sont une bonne chose à utiliser
- mais elles doivent être très régulièrement mise à jour vis à vis du MASTER
Avantages et problèmes :
-
-
- pas de relecture de code possible directement depuis un outil centralisé car les branches locales sont “locales”
Annexes :
sources de réflexion :
Mes propres questions :
Les featureBranch sont bien pratiques. Associées aux PullRequest qui permettent une relecture du code, on a un bon process de relecture obligatoire.
Mais comment s’assurer à tout moment que ma branche featureBranch_xx n’est pas incompatible avec la featureBranch_zzz d’un collègue ?
A lire et relire :
Jenkins
Liens nécessaires :
Pipeline as code
Stack Elastic
A quoi peut servir Elastic Stack (anciennement Stask ELK)
- obtenir rapidement les logs d’un serveur : pour éviter les demandes à l’hébergeur qui, parfois et selon les contrats, peuvent demander 3 jours pour être traitées
- corréler les logs de plusieurs serveur pour avoir une vision d’ensemble d’un processus métier : cas classique des micro-services (dont chaque composant crée ses logs) ou des systèmes SOA
- détecter des problèmes : à partir de données de référence, il est possible de détecter des anomalies (temps de traitement longs, consommation CPU ou mémoire anormale) liées à certains appels au système ou évènement métier
Dans tous les cas, avant de vouloir faire quelque chose d’intelligent avec les données collectées, il faut déjà avoir une idée des éléments à collecter :
- logs applicatifs
- logs d’erreur
- logs de requêtes HTTP
- logs de requêtes SQL
- état physique de la machine (TOP en Unix)
- …
Infrastructure de la Stack Elastic
Classiquement, 3 types d’outils sont mis en oeuvre :
- les sondes qui récupèrent de l’information à leur source :
- la base de données rassemblant toutes les informations :
- l’outil de visualisation des données : Kibana
D’autres outils sont aussi disponibles :
- Kafka qui sert de tampon entre les sondes et ElasticSearch permettant une indisponibilité de ce dernier (mise à jour ou maintenance diverse).
- X-Pack qui apporte à la Stack des fonctionnalités supplémentaires (sécurité, alertes, monitoring, rapports, graphiques et machine learning)
Installation sur un poste Windows
- Télécharger, depuis le site de téléchargement d’Elastic, les outils suivants (en version ZIP pour MS Windows) :
- Kibana
- ElasticSearch
- LogStash
- Extraire toutes les archives
- En option, installer X-Pack en exécutant les commandes :
- depuis le répertoire d’installation d’ElasticSearch :
bin/elasticsearch-plugin install x-pack
- depuis le répertoire d’installation de Kibana :
bin/kibana-plugin install x-pack
- Paramétrer les outils :
- En option pour réaliser un prototype et éviter qu’ElasticSearch n’hurle en cas de problème de disque (source) :
- éditer le fichier elasticsearch.yml
- ajouter
cluster.routing.allocation.disk.threshold_enabled: false
- ou ajouter
cluster.routing.allocation.disk.watermark.high: 99
- Démarrer les outils :
- depuis le répertoire d’installation d’ElasticSearch :
bin/elasticsearch
- depuis le répertoire d’installation de Kibana :
bin/kibana
- Ouvrir Kibana dans un navigateur
Paramétrer une configuration basique
Les configurations suivantes ont été testées pour une version particulière des outils :
- logstash-5.6.0
- kibana-5.6.0-windows-x86
- filebeat-5.6.0-windows-x86_64
- elasticsearch-5.6.0
Un fichier de logs tout bête dans donneesSources\mesLogs.log
coucou madame
bonjour monsieur
coucou monsieur
bonjour madame
hello mademoiselle
hello mademoiselle
Une configuration FileBeat dans configFileBeat\mesLogs_filebeat.yml :
filebeat.prospectors:
- input_type: log
# Déclaration des fichiers sources
paths:
- D:/Projets/Enedis/protoElk/donneesSources/mesLogs.log
# Pour ajouter une information dans tous les logs
fields:
maSource: monFileBeat
output.logstash:
hosts: ["localhost:5043"]
Une configuration LogStash dans configLogStash\meslogs_pipeline.conf :
input {
# Pour prendre les éléments envoyés par Beats
beats { port => "5043" }
}
filter {
# Petit filtre simpliste
grok {
match => { "message" => '%{WORD:formulePolitesse} %{WORD:personneCiblee}' }
}
}
output {
# Pour logger le contenu des messages uniquement dans la console de LogStash
#stdout { codec => plain { charset => "ISO-8859-1" } }
# Pour logger les messages avec leurs metadata
stdout { codec => rubydebug }
# Pour envoyer les logs à ElasticSearch
# @See https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
elasticsearch {
hosts => [ "localhost:9200" ]
# Le nom de l'index doit être en minuscule pour elasticsearch
index => "meslogs"
template => "D:/Projets/Enedis/protoElk/configLogStash/meslogs_template.json"
template_name => "meslogs"
template_overwrite => true
}
}
Un template LogStash dans configLogStash\meslogs_template.json :
{
"template": "meslogs",
"settings": {
"index.refresh_interval": "5s"
},
"mappings": {
"_default_": {
"dynamic_templates": [
{
"message_field": {
"mapping": {
"index": "analyzed",
"omit_norms": true,
"type": "string"
},
"match_mapping_type": "string",
"match": "message"
}
},
{
"string_fields": {
"mapping": {
"index": "analyzed",
"omit_norms": true,
"type": "string",
"fields": {
"raw": {
"index": "not_analyzed",
"ignore_above": 256,
"type": "string"
}
}
},
"match_mapping_type": "string",
"match": "*"
}
}
],
"properties": {
"geoip": {
"dynamic": true,
"properties": {
"location": {
"type": "geo_point"
}
},
"type": "object"
},
"@version": {
"index": "not_analyzed",
"type": "string"
}
},
"_all": {
"enabled": true
}
}
}
}
Et des commandes pour démarrer les outils et nettoyer les répertoires pour répéter le test à l’infini :
- 0-resetTouteLaChaine.cmd :
rmdir filebeat-5.6.0-windows-x86_64\data /Q /S
rmdir logstash-5.6.0\data /Q /S
rmdir elasticsearch-5.6.0\data /Q /S
rmdir kibana-5.6.0-windows-x86\data /Q /S
title Logstash
logstash-5.6.0\bin\logstash -f configLogStash/mesLogs_pipeline.conf --config.reload.automatic
title FileBeats
filebeat-5.6.0-windows-x86_64\filebeat -e -c configFileBeat/mesLogs_filebeat.yml -d "publish"
Une fois la première exécution réalisée sans erreur sur aucune console, sont disponibles :
On obtient ainsi le tableau de bord suivant (après quelques minutes de manipulation dans Kibana) :
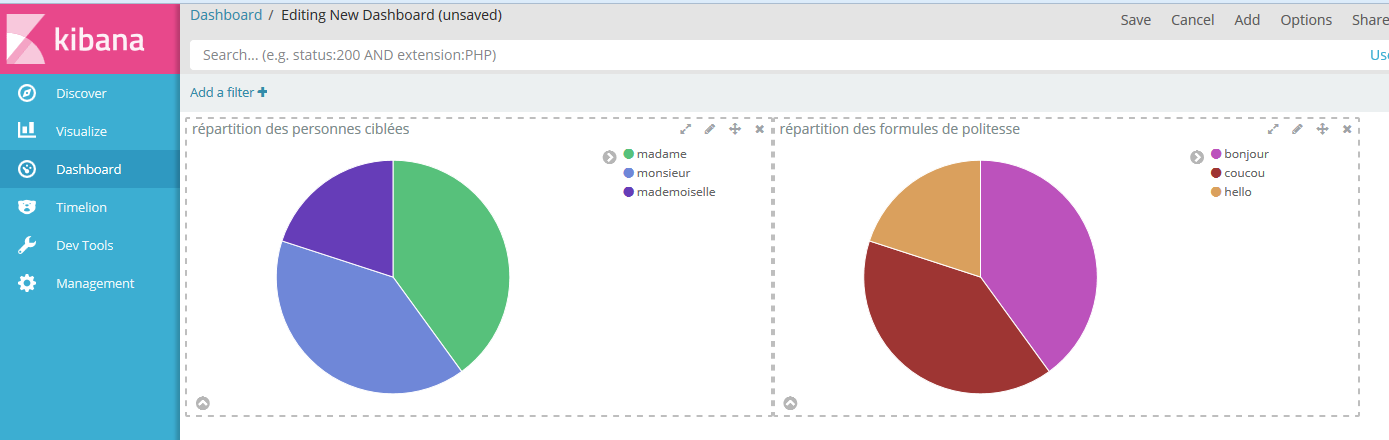
Installation sur un Ubuntu
Git et clefs SSH multiples
Cas d’usage
Quand on développe à la maison et au bureau avec Git, rapidement, apparait le besoin de disposer de plusieurs clefs SSH pour s’authentifier auprès des serveurs.
Etapes :
# Compte perso
Host github.com
HostName github.com
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa_perso
# Compte boulot
Host qsd.mon.boulot
HostName qsd.mon.boulot
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa_boulot
-
Pour déclarer les clefs :
ssh-add ~/.ssh/id_rsa_perso
ssh-add ~/.ssh/id_rsa_boulot
-
Pour démarrer l’agent SSH (ou s’assurer qu’il fonctionne)
eval `ssh-agent -s`
-
Supprimer le cache des clefs
ssh-add -D
Pour tester (si besoin, accepter la connexion en répondant ‘yes’) :
ssh -T git@github.com
ssh -T git@qsd.mon.boulot
ET NE PAS OUBLIER DE FAIRE DES CLONES EN UTILISANT LE PROTOCOLE SSH et non https !!!!
Créer un compte sftp sur AWS
Créer le nouvel utilisateur
Exécuter les commandes :
sudo adduser new_user --disabled-passwordsudo su new_usercdmkdir .sshchmod 700 .sshtouch .ssh/authorized_keyschmod 600 .ssh/authorized_keys
Sécuriser l’accès
- Créer une paire de clef sur la console EC2 d’AWS
- Uploader la clef sur le serveur dans /home/ubuntu
- La transformer en clef publique RSA :
ssh-keygen -f /home/ubuntu/xxx.pem -y >/home/new_user/.ssh/authorized_keys
Feature toggle
Un tout petit billet pour référencer l’article de Fowler sur ce sujet : https://martinfowler.com/articles/feature-toggles.html
Bonnes pratiques d’implémentation des toggles à retenir :
- découpler l’identifiant du toggle et le code activant (ou pas) la sous-fonctionnalité
- remplacer
Festures.isFeatureActive("version-2.0")
- par
Festures.isEnvoiMailConfirmation() { return isFeatureActive("version-2.0"); }
- limiter au maximum les
if. Si plusieurs sont nécessaires, il est préférable de faire des méthodes différentes voire des classes différentes.
Installer une instance WordPress sur Ubuntu
1/ Introduction
Cette procédure a été mise à jour en décembre 2024 lors de la recréation des instances de mes serveurs.
2/ Installation
2.1/ Créer l’infrastructure
Depuis le portail EC2 d’Amazon,
- créer un groupe de sécurité avec les caractéristiques suivantes :
- créer une machine t2.micro (une t2.nano ne permet pas d’installer MySQL par manque de mémoire)
- s’y connecter via le navigateur
- mettre à jour la machine avec les commandes
sudo apt-get update
sudo apt-get -y upgrade
Pour obtenir, à coup sûr, l’IP publique de la machine, exécuter la commande :
2.2/ Faire pointer le DNS
Depuis votre fournisseur de DNS, créer l’entrée suivante :
- de type A, faire pointer me.guillaumetalbot.com vers l’IP publique de la machine EC2
2.3/ Installer apache2
Pour installer apache2, exécuter les commandes :
sudo apt-get -y install apache2
sudo a2enmod proxy proxy_http headers ssl rewrite
sudo systemctl restart apache2
Pour vérifier que le service est démarré et le serveur accessible, ouvrir un navigateur avec l’adresse http://xxx.xxx.xxx.xxx avec xxx.xxx.xxx.xxx l’IP obtenue de la commande précédente.
Pour déclarer un premier vhost HTTP écoutant sur le port 80 (temporaire évidemment), créer le fichier sudo vi /etc/apache2/sites-available/vHostHttp.conf
<VirtualHost *:80>
ServerAdmin webmaster@localhost
ServerName me.guillaumetalbot.com
ServerAlias ci
</VirtualHost>
Pour activer le nouveau vhost et désactiver le vhost par défaut
sudo a2ensite vHostHttp
sudo a2dissite 000-default.conf
sudo a2disconf localized-error-pages.conf charset.conf serve-cgi-bin.conf
sudo systemctl reload apache2
Pour limiter les informations fournies par le serveur dans les entêtes de réponse, modifier la configuration de sécurité via la commande
sudo vi /etc/apache2/conf-available/security.conf
Puis modifier (en commentant, décommantant ou modifiant les lignes) pour obtenir
- la clef ServerTokens avec la valeur Prod
- la clef ServerSignature avec la valeur Off
- la clef TraceEnable avec la valeur Off
- la configuration de l’entête Header set X-Content-Type-Options: “nosniff”
- la configuration de l’entête Header set Content-Security-Policy “frame-ancestors ‘self’;”
Pour prendre en compte les modifications, exécuter la commande
sudo systemctl reload apache2
2.4/ Installer CertBot
** Il faut que la configuration DNS soit active et propagée pour installer CertBot. **
Pour tester la configuration DNS, tenter d’accéder au site http://me.guillaumetalbot.com et vérifier que la page par défaut d’Apache2 s’affiche.
Puis suivre les instructions du site https://certbot.eff.org/instructions en y sélectionnant Apache et le bon OS.
Si la procédure n’a pas changée, cela se résume aux commandes suivantes (à vérifier tout de même) :
sudo snap install --classic certbot
sudo ln -s /snap/bin/certbot /usr/bin/certbot
sudo certbot --apache
Pour tester le bon fonctionnement du site en HTTPs, tenter d’accéder au site https://me.guillaumetalbot.com et vérifier que la page par défaut d’Apache2 s’affiche.
Pour désactiver l’accès HTTP, réaliser les actions :
- modifier le fichier
sudo vi /etc/apache2/ports.conf pour en supprimer la ligne Listen 80
- exécuter les commandes :
sudo a2dissite vHostHttp
sudo systemctl reload apache2
2.5/ Installer les prérequis à WordPress
** Une bonne procédure de référence est disponible sur le site ubuntu-fr.org*
Pour installer des utilitaires précieux, exécuter la commande :
sudo apt-get install unzip
Pour installer MySQL, exécuter la commande :
sudo apt install mysql-server
Pour paramétrer MySQL, exécuter les commandes :
sudo mysql
> CREATE DATABASE wordpress DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
> CREATE USER 'wordpressuser'@'localhost' IDENTIFIED BY 'un_mot_de_passe_a_choisir_et_stocker_dans_keepass';
> GRANT ALL ON wordpress.* TO 'wordpressuser'@'localhost';
> FLUSH PRIVILEGES;
> EXIT;
Pour installer PHP, exécuter la commande :
sudo apt install php php-mysql php-curl php-gd php-intl php-json php-mbstring php-xml php-zip libapache2-mod-php
2.6/ Installer WordPress
Pour paramétrer Apache2,
- modifier le fichier
sudo vi /etc/apache2/sites-enabled/vHostHttp-le-ssl.conf pour y ajouter, sous ServerAlias, les lignes suivantes :
DocumentRoot /var/www/wordpress
<Directory /var/www/wordpress>
AllowOverride all
Require all granted
</Directory>
- puis exécuter la commande
sudo systemctl reload apache2
Pour installer WordPress, exécuter les commandes :
cd
pwd
wget https://fr.wordpress.org/wordpress-latest-fr_FR.zip
sudo unzip wordpress-latest-fr_FR.zip -d /var/www
sudo chown www-data:www-data /var/www/wordpress -R
sudo chmod -R -wx,u+rwX,g+rX,o+rX /var/www/wordpress
Pour paramétrer WordPress, accéder à la page https://me.guillaumetalbot.com/ et laisser WordPress guider via son interface de paramétrage.
Une fois l’interface d’administration affichée, voici quelques étapes incontournables :
- dans le menu Extensions > Ajouter une extension
- installer puis activer WP Super Cache
- installer puis activer Yoast SEO
- installer puis activer FileBird
- installer puis activer UpdraftPlus
- installer puis activer CC Child Pages
- dans le menu Réglages > WP Super Cache
- sélectionner l’option Mise en cache activée (Recommandé) et cliquer sur Mettre à jour l’état
- dans le menu UpdaftPlus puis l’onglet Réglages
- sélectionner les deux planifications mensuelles avec une rétention de 1
- mettre en place la sauvegarde distante (non détaillée ici)
- dans le menu Yoast SEO
- dérouler la procédure de configuration minimale
- dans le sous-menu Réglages,
- activer Suivi d’utilisation
- dans Réglages essentiels, renseigner le formulaire
- enregistrer les modifications
- dans le menu Extensions > Extensions installées
- supprimer Hello Dolly
- supprimer Akismet Anti-spam: Spam Protection
- activer la mise à jour automatique pour toutes les extensions
- dans le menu Comptes > Ajouter un compte
- créer un compte pour chaque personne en ayant besoin
- dans le menu Réglages > Lecture
- définir la page par défaut du site (pas celle des articles)
- dans le menu Apparence > Thèmes
- installer le thème NewsBlogger
Git et les mots de passe
1/ Résumé
La (grande?) majorité des développeurs utilisent aujourd’hui GIT pour sauvegarder et partager leurs développements.
Tout y est stocké. Et, parfois, même les mots de passe (clefs, secrets, …) !!
La solution optimale serait de ne pas les insérer dans le dépôt GIT. Mais cela signifie ne plus les partager avec le reste de l’équipe.
Une autre solution consiste à chiffrer ces informations avant de les partager sur le repository commun sans oublier de les déchiffrer sur le repository local.
Une solution (parmis d’autre) est Transcrypt.
2/ Qu’est-ce que Transcrypt ?
Transcrypt est un outil permettant d’initialiser le chiffrement de certains fichiers dans un dépôt Git.
Une fois le dépôt paramétré, Transcrypt n’est plus nécessaire et peut être désinstallé.
La liste des fichiers à chiffrer avant (et déchiffrer après) chaque commit est paramétrée dans le fichier .gitattributes
3/ Par quoi commencer ?
-
La toute première chose à faire est d’identifier les fichiers contenant des secrets dans l’historique GIT. Pour cela, l’outil GitLeaks est bien utile.
- Télécharger une version compatible avec le poste de développement depuis la page de téléchargement.
- Extraire le contenu de l’archive dans un répertoire dédié en dehors du clone du dépôt.
- Ouvrir une invite de commande dans le clone à analyser
- Exécuter la commande
xxx/gitleaks_xxxx/gitleaks.exe git --report-path gitleaks-report.json
- Le fichier gitleaks-report.json contient alors tous les secrets détectés
- S’assurer que le fichier ne contient aucun caractère # (sinon la commande SED est KO)
- Extraire la liste des fichiers et secrets avec le pattern
^.*"(File|Secret)".*$
- Mettre sur une même ligne le secret et le nom de fichier
- Eliminer les doublons
- Faire des chemins de fichier des chemins absolus
- Mettre en forme chaque ligne pour obtenir
sed -i "s#LE_SECRET_ISSU_DE_GITLEAK#xxxxxxxx#g" "LE_NOM_DE_FICHIER_ISSU_DE_GITLEAK"
- Sauvegarder l’ensemble des commandes dans un script shell déposé à la racine du dépôt
-
La seconde étape est de faire disparaître de l’historique GIT le(s) secret(s). Pour cela, il suffit
- télécharger l’outil BFG depuis la page officielle
- créer un fichier contenant, sur une ligne différente, chaque secret venant du fichier généré par GitLeaks
- après avoir retiré le caractère = en fin de secret
- suffixé par
==>xxxxxxxx
- exécuter les commandes
java -jar /d/xxxx/bfg.jar --replace-text /d/xxx/password.txt "/d/cheminVersDepot"
cd /d/cheminVersDepot
git reflog expire --expire=now --all && git gc --prune=now --aggressive
- Une fois les secrets supprimés, relancer l’analyse avec la commande précédete
4/ Pour initialiser un dépot avec Transcrypt
- Installer Transcrypt :
- Dans un répertoire d’outillage, exécuter la commande suivante pour récupérer la dernière version de l’outil :
git clone https://github.com/elasticdog/transcrypt.git
- Ajouter le répertoire nouvellement créé dans la variable d’environnement PATH
- Ouvrir une nouvelle invite de commande dans tout autre répertoire (pour être certain que la dernière valeur de PATH est utilisée)
- Y exécuter la commande pour vérifier que le script est bien accessible partout (l’aide de Transcrypt doit s’afficher)
transcrypt --help
- Initialiser le chiffrement dans le dépôt :
- Depuis une invite de commande, se positionner dans le répertoire du dépôt à traiter
- Y exécuter la commande
transcrypt
- Répondre aux questions posées
- Conserver le mot de passe généré (ou saisi) dans votre Keepass
- Ajouter un fichier et déclarer qu’il doit être chiffré :
- Ajouter le fichier normalement :
git add le/chemin/du/fichier.extension
- Ajouter la ligne suivante dans le fichier .gitattributes
le/chemin/du/fichier.extension filter=crypt diff=crypt merge=crypt
Voici un exemple pour un fichier environment d’Angular :
projects/coupeDesMaisons/src/environments/environment.prod.ts filter=crypt diff=crypt merge=crypt
Rédiger dans WordPress
1/ Introduction
Cette page contient des notes prises durant la refonte d’un site WordPress d’une association dont je fais partie.
2/ Règles de base
R1/ Si l’information est effémère ou liée à un évènement ponctuel, l’information doit faire l’objet d’un ARTICLE. Sinon ce sera une PAGE.
R2/ Si une image doit être publiée, il faut :
- accéder à la page Médias > Médiathèque
- sélectionner (ou créer) un répertoire correspondant à la PAGE ou à l’ARTICLE dans laquelle la photo doit apparaître
R3/ Si toutes les images d’un répertoire doivent être insérées dans une unique galerie, le bloc FileBird Galery est à utiliser de préférence car il permet d’afficher toutes les images d’un répertoire
- une fois le bloc inséré, sélectionner le répertoire dans la barre latérale à droite
- sélectionner le nombre de colonnes voulues (1 seule si une seule image, …)
- activer/désactiver le crop pour vérifier si des images sont dénaturées et sélectionner la meilleure option
- tester la valeur Masonry du paramètre Layout pour obtenir, potentiellement, un meilleur rendu
R4/ Si seules quelques images d’un répertoire doivent être insérées, le bloc Galerie doit être utilisé.
R5/ Si une unique image doit être insérée et qu’un texte doit y être associée, le bloc Média & texte doit être utilisé.
R5/ Avant toute publication, doivent être vérifiés les éléments suivants :
- supprimer les doubles espaces
- supprimer les espaces avant une virgule ou un point
- les siècles sont au format romain avec le ème en exposant
R6/ Tous les liens pointant vers un autre site doivent s’ouvrir dans un nouvel onglet.
3/ Rédiger un article
Ra1/ Le titre d’un article commence par la date de l’évènement ou, à défaut, par le date de publication.
Ra2/ Si l’information est une copie d’un article de presse, l’article de notre site doit :
- fournir la source :
Source : https://www.leberry.fr/baugy-18800/travaux-urbanisme/une-premiere-tranche-des-travaux-de-renovation-de-l-eglise-de-baugy-achevee_14562797/
- mettre le contenu de l’article de presse dans un bloc Citation
- ne rien modifier dans le texte de l’article de presse
- ajouter toute remarque/complément/… en dehors du bloc Citation
Ra3/ Avant de publier un article,
- dans la barre latérale droite, dans l’onglet Article, doivent être
- être sélectionnée, a minima, une catégorie (l’année)
- vérifiée/modifiée la date de publication présente dans le champs Publier
- vérifiée la lisibilité de l’article
4/ Rédiger une page
Rp1/ A la création de la page, dans la barre latérale droite, dans l’onglet Page, il est préférable de, tout de suite, saisir la page parente dans le paramètre Parent.
Rp2/ Toute page parente dont introduire les pages filles. Pour créer une liste de lien vers les pages filles, insérer un bloc Code court avec le contenu [child_pages list="true" orderby="title" order="ASC"]
4.1/ Les blocs utiles
Pour insérer une image avec du texte dessus (utile en début d’une page), il faut utiliser un bloc bannière.
Pour mettre en forme des contenus les uns à côté des autres, existe le bloc colonnes (attention, pour une image et un texte, utiliser le bloc Média & texte).
Pour mettre en place des onglets, il suffit
- d’insérer les trois blocs Code court suivants :
[tabby title="Titre du premier onglet"][tabby title="Titre du second onglet"][tabbyending]
- d’ajouter le contenu du premier onglet sous le titre du premier onglet
- d’ajouter le contenu du second onglet sous le titre du second onglet
- d’ajouter, à volontée, un titre et un contenu d’onglet avant le dernier Code court
Pour permettre de cliquer sur une image pour qu’elle s’affiche en grand, il suffit de
- depuis l’éditeur, cliquer sur l’image
- au dessus de l’image, cliquer sur l’icône Lien
- sélectionner Agrandir au clic
5/ Les choses à savoir
Si, après avoir enregistrer des modifications, ces dernières ne sont pas visibles, il suffit de cliquer sur le bouton *Purger le cache" présent tout en haut des pages d’administration de WordPress (hors de l’éditeur de page ou d’article).
Trucs à lire
Quelques trucs à lire